

Michio Kaku's Strange Joe Rogan Appearance
Debunking a great physicist's claims on Joe Rogan: quantum computers as fact checkers, and how LLMs work.

Earlier this week, the physicist Michio Kaku made an appearance on the Joe Rogan podcast, where he discussed, among other things, AI and quantum computing. Their discussion made it clear that Kaku doesn’t know anything about the modern incarnation of AI.
Let me say that Kaku is undoubtedly a smart person and an expert physicist. But he is not an expert in AI. These two things are not mutually exclusive — expertise is not universal. I would take John Danaher’s advice on how to hit a blast double, but not on what to wear to a wedding.

I’m talking here to whoever left this comment on my YouTube video about this:

Given the scale of Joe Rogan’s platform, Kaku’s comments have already been picked up by other outlets like the New York Post, amplifying his strange and unfounded claims that quantum computing will be a panacea to the failures of AI. This is not the case — but to explain why, let’s start from the beginning.

Kaku begins by describing ChatGPT as follows:
AI is a software program. We're talking about homogenizing different kinds of essays on the web, splicing them together, and then passing it off as your latest creation.
I think most people understand that this is not how large language models (LLMs) like ChatGPT work. LLMs don’t simply store their training data somewhere, retrieve relevant segments upon request, and concatenate them like a video editor making jump cuts. Rather, they internalize language understanding through exposure to Internet-scale datasets — in ways that are both complex and uninterpretable.
There are three phases in training these models. They are first trained to predict the next piece of language — called a token, which can be a word or a sub-word like “-ly” or “ph-” — from the preceding sequence of tokens.
So given a sentence like, “I love cats” — the LLM’s first task would be to predict “love” from “I,” then “cats” from “I love.” This is a simple task — but repeated over billions of sentences, a sufficiently large LLM performing this task well can encode an understanding of how language works.
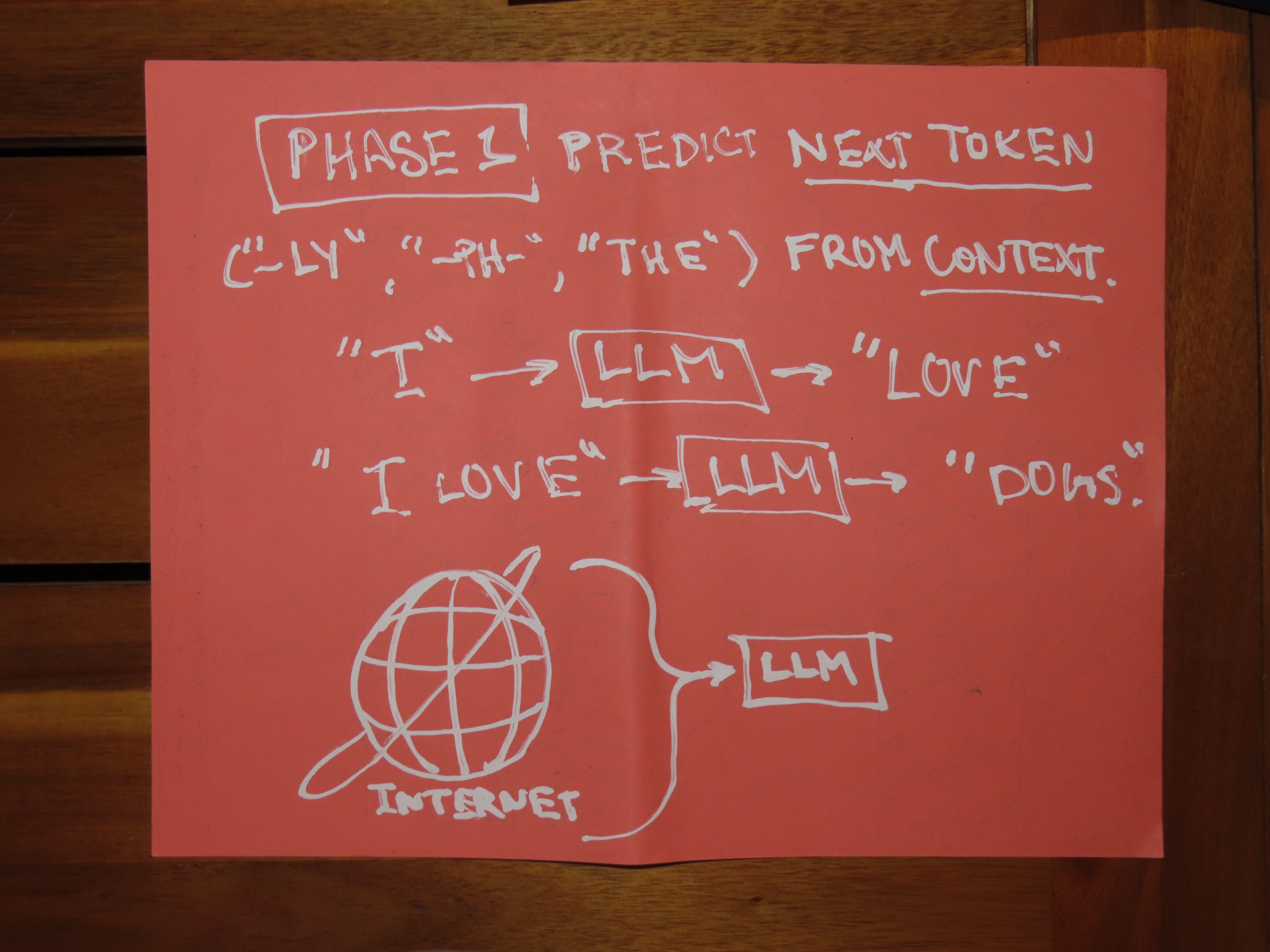
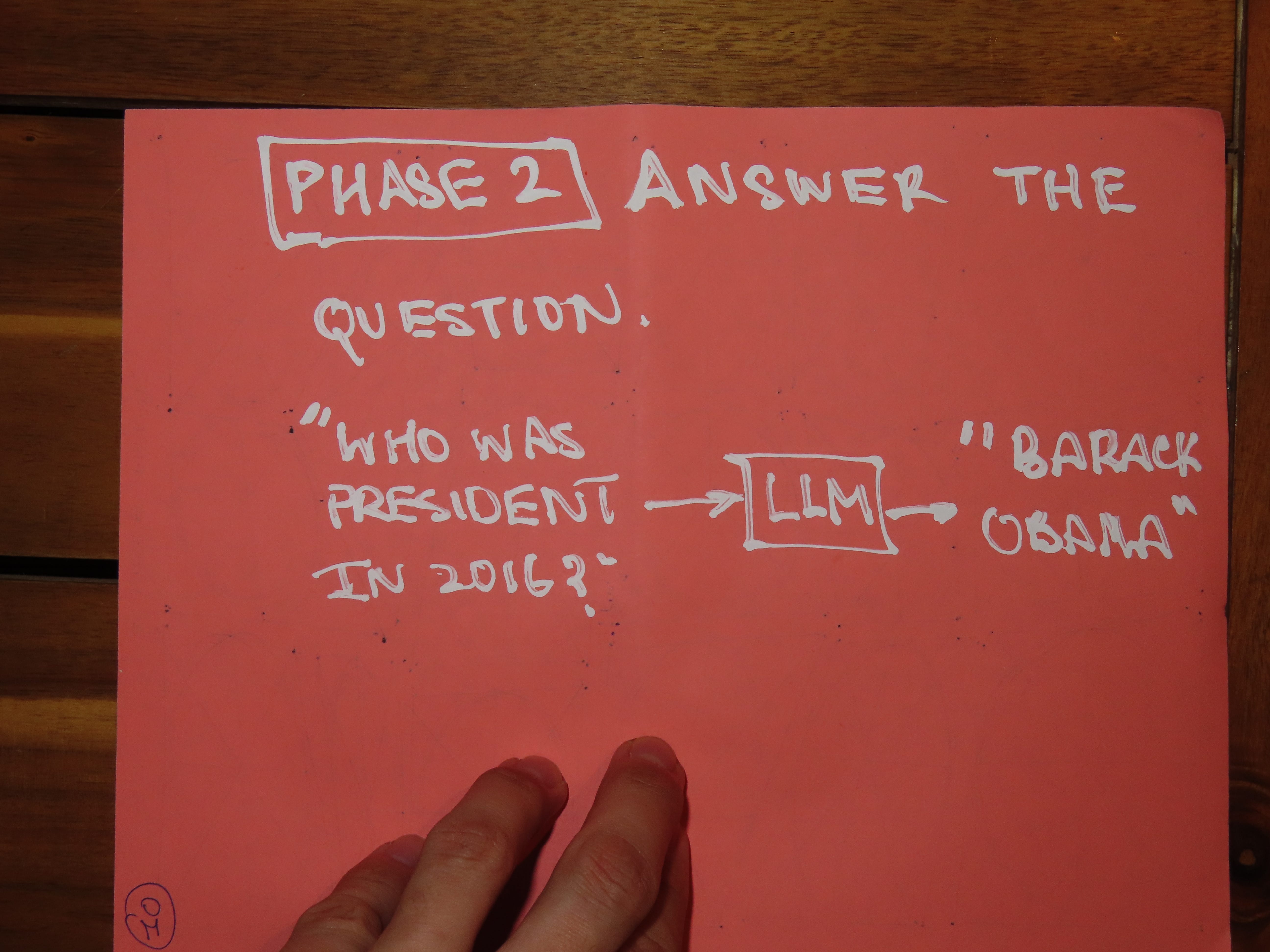
Once the LLM performs well on this next-token prediction task (called “causal language modelling”) it’s trained on specific datasets containing questions and answers to predict answers from questions. So given the question, “Who was president in 2016?” the LLM’s task is to predict, “Barack Obama.” After this phase, the LLM is not just a general student of language — it’s specifically tailored toward answering questions.
Finally, in a third step, the LLM is trained via human feedback to produce answers viewed by humans as high quality, relevant, and appropriate.
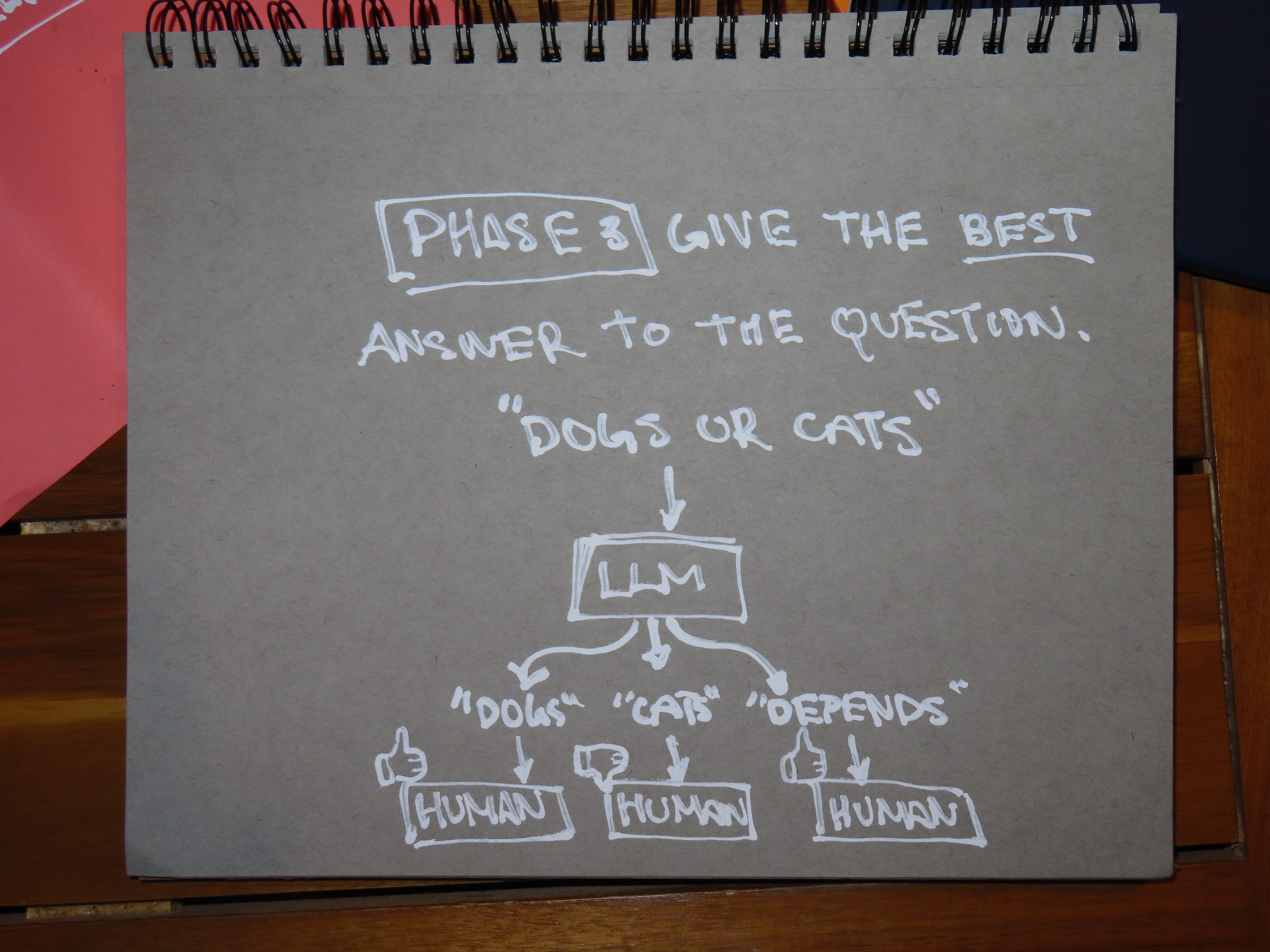

This means, critically, that LLMs are not simply splicing together phrases from their training sets, as Michio Kaku suggests. This is more than a semantic distinction. Kaku’s description of LLMs leads him to identify this failure mode:
If you're a high school kid, you could write all sorts of science fiction scenarios, and some chatbot may grab pieces of that nonsense and incorporate it into their essay.
Which is… very unlikely. For the following reason: let’s say this (brilliant) student writes a story that begins with:
“In the week before their departure to Arrakis, when all the final scurring about had reached a nearly unbearable frenzy, an old crone came to visit the mother of the boy, Paul.”
ChatGPT sees this story in its training set — along with every book ever written, every newspaper article ever published, every blog post on Substack, and every comment on Reddit. The student’s story gets “diluted” by all the other texts on the Internet similar to it. Even when prompted with the first few words — “In the week before their departure” — the LLM’s task remains to predict the most probable next token. In training, the LLM has consumed every blog post that mentions “departing to Paris,” every YouTube vlog about a flight whose “departure is delayed,” and every New York Times story about a lawmaker’s “departure from the norm.” So there are many plausible continuations to the sentence, “In the week before their departure” — and our hypothetical student’s science fiction story is exactly one such continuation in a massive ocean of probability.
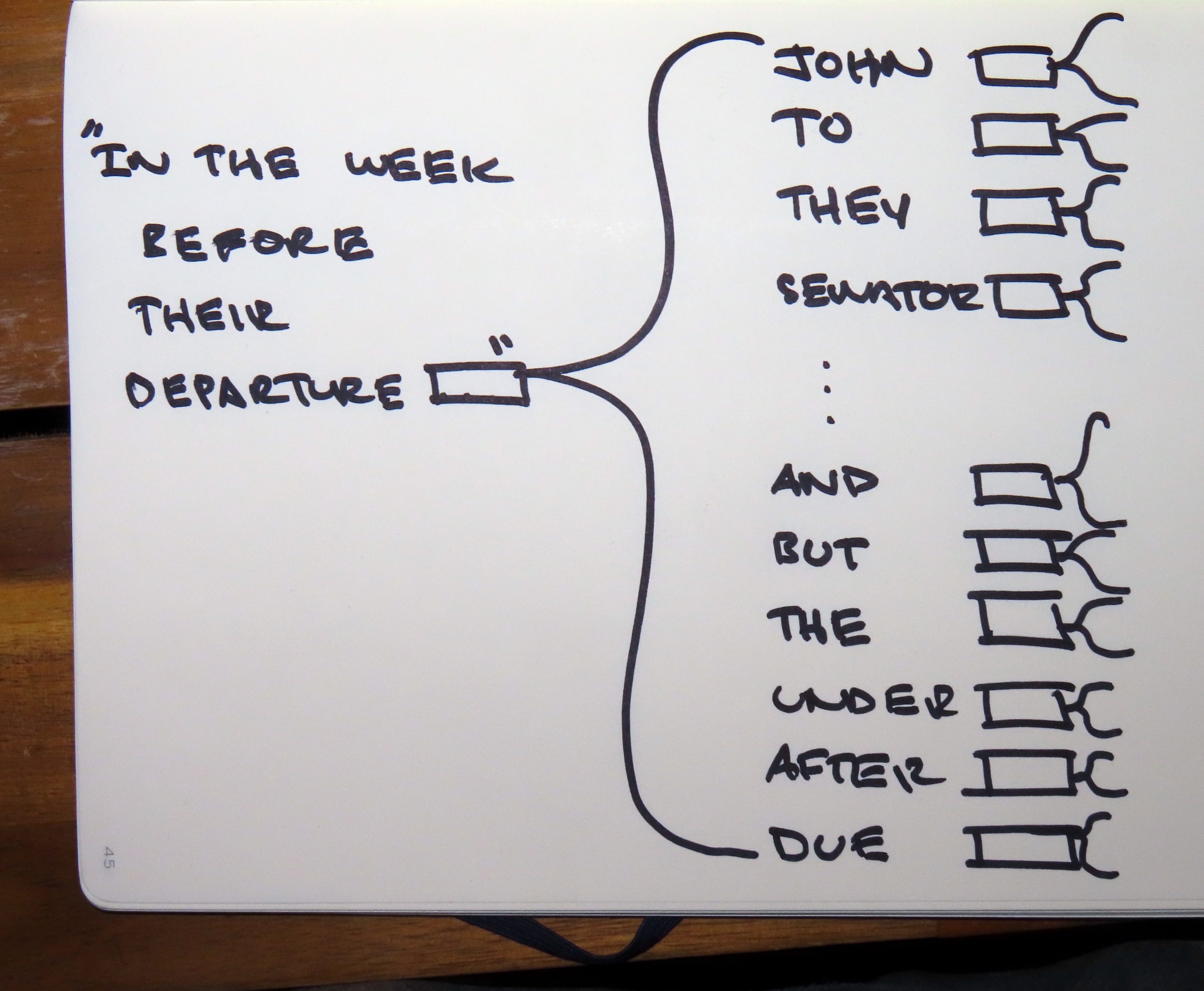
As such, it becomes exceedingly improbable for the LLM to reproduce the story word-for-word.


People in the comments of the podcast video were quick to call Kaku out on his fundamental misunderstanding of LLMs. But few people commented on his even stranger claim that quantum computing could resolve a stubborn failure mode for LLMs.
They cannot tell the difference between what is false and what is true. If you talk to the chatbot and say, “Do you know the difference between correct and incorrect?” they say, “No.”
It’s true that LLMs can confidently produce factually incorrect statements. This failure mode, called “hallucination” in the field, is a well-studied and pernicious one. There are several schools of thought in AI regarding how to resolve hallucination, most involving techniques called “grounding.” Some researchers believe that training models on multiple kinds of data, like images, text, and video, is the answer. These researchers believe that exposure to multiple kinds of data forces models to link their understanding of language to understanding of the visual world — so that when the model outputs the word “chair,” it can be verified in an image that it really knows what “chair” means. This is called “visual grounding.”
Other researchers believe that models need to build explicit sets of facts, called “knowledge bases,” to be grounded. They can then learn when and how to query their knowledge bases to produce factually correct answers to queries. This is called “knowledge grounding.”
Still other researchers believe that systems have to be “embodied” — they have to interact with the real, physical world, as robots do — in order to be truly grounded.
Apologies for the jargon, but I’m trying to make a point. Kaku is correct when he says:
There is no fact checker for chatbots. Let me repeat that again: there is no fact checker for chatbots… That's the reason why they're so dangerous.
But this is a well-known, well-studied problem with an established research community looking to solve it. While there is no single accepted solution right now, the problem arises entirely from “software programs,” to quote Kaku — and its resolution will arise from “software programs” as well.
Not only is this the consensus in the AI community, but it’s common sense for reasons I’ll explain in a moment. Which makes it perplexing why Kaku states out of the blue, with no justification, that:
Quantum computers can act as a fact checker. You can ask a quantum computer to remove all the garbage, remove all the nonsense, in these articles, and it'll do that. So in other words, the hardware may be a check on some of the wild statements made by software.
Quantum computers are a promising technology — but their fundamental appeal is that they exponentially increase computational power. “Fact checking” systems are not bottlenecked by hardware. Hallucination remains an unsolved problem not because the AI systems are too limited in their computational power, or because grounding methods are infeasible with our current computational power. These problems remain unsolved not because our computers aren’t fast enough to solve them, but rather because the perfect “fact checking” software doesn’t yet exist — we don’t yet know how to build it. We don’t yet understand what structures or logics should govern “fact checking.”
It’s not clear why Kaku thinks a hardware innovation would solve what is fundamentally a software problem. He doesn’t elaborate. But even if quantum computers were readily deployable, we would still have to devise entirely new algorithms to “remove all the nonsense” from AI-generated text or training datasets. These algorithms would run just as well on traditional computers as on quantum computers.
